基于Flink的实时商品推荐系统架构分析
一、引言
在电商、内容平台和各类在线服务领域,个性化推荐系统已成为提升用户体验、增加用户粘性和驱动业务增长的核心引擎。传统的批处理推荐系统虽能分析历史数据,但无法实时捕捉用户瞬息万变的兴趣和行为,存在明显的反馈延迟。Apache Flink作为一个开源的流处理框架,以其高吞吐、低延迟、精确的状态管理和出色的容错机制,为构建新一代实时推荐系统提供了理想的底层支撑。本文旨在对基于Flink的商品推荐系统进行全面的计算机系统分析,探讨其架构设计、核心流程、关键技术与挑战。
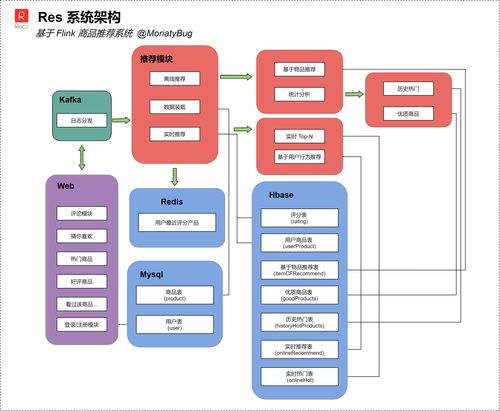
二、系统总体架构
一个典型的基于Flink的实时推荐系统通常采用分层、模块化的设计思想,整体架构可分为数据采集层、实时处理层、在线服务层和存储层。
- 数据采集层:负责从各业务端(如APP、Web、服务器日志)实时采集用户行为事件流,包括浏览、点击、搜索、加购、购买等。常用工具包括Flume、Kafka Connector、或直接通过SDK将数据发送至消息队列(如Apache Kafka)。Kafka作为高可靠的消息总线,起到了解耦和数据缓冲的作用。
- 实时处理层(Flink核心层):这是系统的“大脑”。Flink作业从Kafka消费原始事件流,进行一系列实时计算:
- 数据清洗与格式化:过滤无效数据,将异构数据转换为统一的格式。
- 特征实时计算与更新:这是推荐算法的基石。Flink利用其状态(State)管理能力,实时维护和更新用户画像(如近期兴趣标签、购买力)和商品画像(如实时热度、点击率)。例如,通过滑动窗口统计过去一小时商品的点击量。
- 实时匹配与排序:根据触发事件(如用户进入某个页面),结合实时更新的用户和商品特征,调用轻量级的召回模型(如基于实时协同过滤的相似商品召回)和排序模型(如实时CTR预估模型),在毫秒级内生成个性化推荐列表。模型本身可以通过在线学习(Online Learning)方式,由Flink流实时更新模型参数。
- 在线服务层:接收Flink处理层输出的实时推荐结果(通常写入高速缓存如Redis),并通过低延迟的RPC API(如gRPC、HTTP)向客户端提供推荐服务。有时为了应对超高并发,该层还需承担简单的业务逻辑处理和结果融合(如将实时结果与离线推荐结果混合)。
- 存储层:分为在线存储和离线存储。
- 在线存储:使用Redis、Aerospike等内存数据库,存储需要极快读写的实时特征和临时推荐结果。
- 离线/批处理存储:使用HDFS、HBase、或数据湖(如Iceberg),存储全量历史数据,用于训练更复杂的离线模型、进行深度数据分析以及作为Flink状态故障恢复的备份。
三、核心处理流程与Flink应用
在Flink作业内部,数据处理流程是一个有向图,主要涉及以下几个关键算子:
- Source:从Kafka主题消费用户行为事件流,构成DataStream。
- 实时特征工程:
- 用户行为序列构建:使用
KeyedStream按用户ID分区,结合ProcessFunction和状态(ValueState或ListState)维护用户近期的行为序列,用于实时序列推荐。
- 统计型特征计算:使用
Window操作(如滑动窗口、会话窗口)对商品或类目进行聚合计算(计数、求和),得到实时热度、点击率等特征。Flink的窗口机制和事件时间处理保证了在乱序数据流中计算的准确性。
- 模型推理与更新:
- 对于已部署的深度学习排序模型,可以通过Flink的异步I/O功能,并发地查询外部特征库(如Redis)获取特征,并调用TensorFlow Serving或自研的模型服务进行实时推理。
- 对于在线学习场景,可以将(用户特征,反馈结果)作为训练样本流,通过Flink的
CoMapFunction或自定义算子,逐步更新一个轻量级模型(如逻辑回归、FTRL)的参数,并实时将新参数同步到在线服务。
- Sink:将处理后的实时推荐列表、更新后的特征或模型参数,写入到下游系统,如Redis(供在线服务读取)、Kafka(用于其他系统订阅)或数据库。
四、关键技术考量与挑战
- 状态管理与容错:推荐系统的状态(用户画像、实时计数)至关重要。Flink提供了强大的状态后端(如RocksDB)和基于Chandy-Lamport算法的精确一次(Exactly-Once)容错保证(Checkpoint机制),确保系统故障时状态不丢失、不重复。这是构建可靠实时系统的关键。
- 数据流与维表关联:实时流(行为事件)需要与相对静态的维表(商品信息、用户属性)进行关联(Join)。Flink提供了多种方式:
- 预加载维表:在算子初始化时加载全量维表到内存,适合小维表。
- 热存储查询:通过异步I/O查询Redis等外部存储,适合大维表,但需注意缓存一致性和查询延迟。
- 时序数据库关联:将维表变更也作为流,使用双流Join。
- 窗口与乱序处理:网络延迟会导致事件乱序到达。Flink的
Watermark机制允许应用定义最大乱序时间,在窗口触发计算时,能尽可能包含迟到但合理的数据,平衡了计算的完整性和实时性。 - 系统性能与资源管理:实时推荐对延迟极其敏感(通常要求在百毫秒内)。需要精细调优Flink作业的并行度、网络缓冲区、状态后端配置,并合理设置Kafka分区数,确保数据均匀分布,避免数据倾斜导致瓶颈。在Kubernetes或YARN上部署时,需做好资源隔离与弹性伸缩。
- 算法与工程的结合:实时推荐不仅是流处理工程问题,更是算法问题。如何设计低延迟、高效率的实时召回与排序算法,如何将离线训练的复杂模型(如深度神经网络)高效地部署到流式计算管道中,并实现特征的实时拼接与对齐,是算法工程师与系统架构师需要紧密协作解决的难题。
五、与展望
基于Flink的商品推荐系统代表了推荐技术向实时化、智能化演进的重要方向。它通过统一的流处理架构,将数据采集、特征计算、模型推理与更新等环节无缝衔接,实现了“数据即产生即处理,模型即反馈即更新”的闭环。这不仅极大地提升了推荐的时效性和相关性,也为探索更复杂的在线学习和强化学习推荐算法提供了强大的系统基础。
随着Flink ML库的完善、与深度学习框架更深的集成(如Alink),以及流批一体技术的成熟,实时推荐系统的构建将变得更加高效和标准化。如何在保障高性能和低延迟的前提下,进一步提升系统的可解释性、公平性和隐私保护能力,将是学术界和工业界持续关注的前沿课题。
如若转载,请注明出处:http://www.maskpolo.com/product/29.html
更新时间:2026-06-19 07:24:32